lucene简介和索引原理
1 Lucene简介
Lucene是一个高效,全Java实现、开源、高性能、功能完整、易拓展,支持分词以及各种查询方式(前缀、模糊、正则等)、打分高亮、列式存储(DocValues) 的全文检索库。仅支持纯文本文件的索引和搜索。
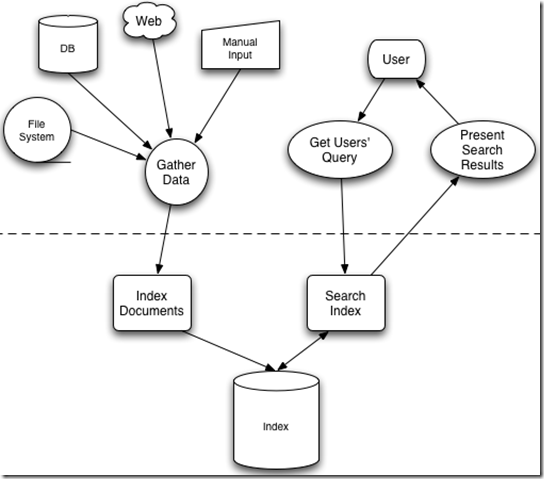
2 lucene索引原理
每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表

2.1 索引创建过程
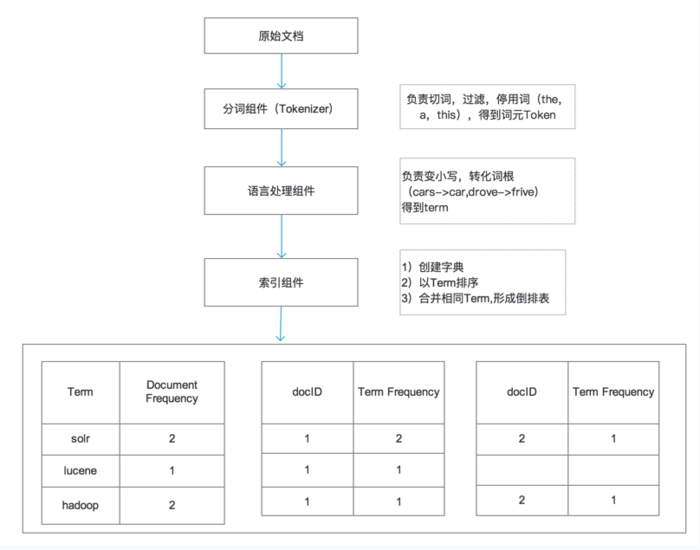
1.需要被索引的原文档(document)
2.将原文档传给分词组件(Tokenizer),分词后得到词元(Token)
3.将得到的词元(Token)传给语言处理组件(Linguistic Processor),进行一些语法转化:包括字母转为小写、缩减(复数变单数)、转变(过去时转变为词根),将词语转化为词根(Term)
4.将得到的词(Term)传给索引组件(Indexer),得到词典和倒排链表(反向索引表)
5.通过索引存储将索引写入硬盘
2.2 检索过程

1.用户输入查询语句
2.对查询语句进行词法分析得到单词以及关键字(关键字有AND, NOT),然后对得到的单词进行语言处理(同索引过程中的语言处理几乎相同)得到查询词根Term
3.语法分析,根据查询语句的语法规则来形成一棵语法树。
4.通过索引存储将索引读入到内存。
5.利用查询树搜索索引,从而得到每个词(Term) 的文档链表,对文档链表进行交,差,并得到结果文档
6.根据得到的文档和查询语句的相关性,对结果进行排序。(向量空间模型算法:通过各个关键词根在不同文档中的权重来比较文档与查询语句的相关性)
2.3 lucene索引基本概念
- 索引(index)
- 在Lucene中一个索引是放在一个文件夹中的
- 段(segment)
- 一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并
- 文档(document)
- 文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档
- 新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中
- 域(field)
- 一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等,都可以保存在不同的域里
- 词(term)
- 词是索引的最小单位,是经过词法分析和语言处理后的字符串
Lucene的索引结构中,即保存了正向信息,也保存了反向信息
- 正向信息:按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term),也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词
- 反向信息:保存了词典到倒排表的映射:词(Term) –> 文档(Document)
2.4 lucene结构
全文索引绝大多数是通过倒排索引来做,倒排索引由两个部分组成,即词典和倒排表
2.4.1 索引结构
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间,压缩率一般在3倍~20倍之间;
2)查询速度快。O(len(str))的查询时间复杂度。
3) 模糊查询支持比较好
4)输入要求有序,更新较为困难
索引文件: 我们往索引库里插入四个单词abd、abe、acf、acg,看看它的索引文件内容
- tip部分,每列一个FST索引,所以会有多个FST,每个FST存放前缀和后缀块指针,这里前缀就为a、ab、ac
- tim里面存放后缀块和词的其他信息如倒排表指针、TFDF等
- doc文件里就为每个单词的倒排表。
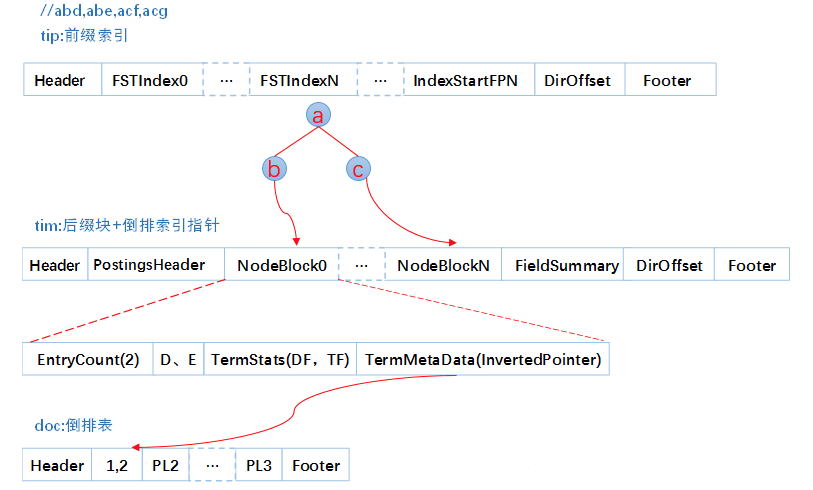
所以它的检索过程分为三个步骤:
- 内存加载tip文件,通过FST匹配前缀找到后缀词块位置。
- 根据词块位置,读取磁盘中tim文件中后缀块并找到后缀和相应的倒排表位置信息。
- 根据倒排表位置去doc文件中加载倒排表
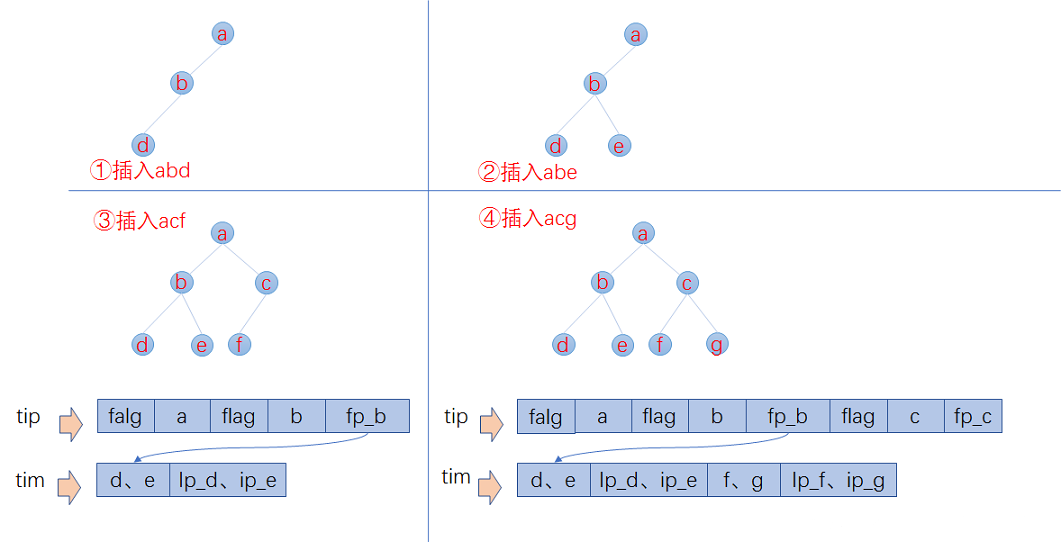
- 插入abd时,没有输出
- 插入abe时,计算出前缀ab,但此时不知道后续还不会有其他以ab为前缀的词,所以此时无输出。
- 插入acf时,因为是有序的,知道不会再有ab前缀的词了,这时就可以写tip和tim了,tim中写入后缀词块d、e和它们的倒排表位置ip_d,ip_e,tip中写入a,b和以ab为前缀的后缀词块位置
- 插入acg时,计算出和acf共享前缀ac,这时输入已经结束,所有数据写入磁盘。tim中写入后缀词块f、g和相对应的倒排表位置,tip中写入c和以ac为前缀的后缀词块位置
2.4.2 倒排表结构
Lucene现使用的倒排表结构叫Frame of reference
数据压缩: 下图:将6个数字从原先的24bytes压缩到7bytes 注:step1到step2的得到的新数组是后尾数减去前位数得到的

跳跃表加速合并: 因为布尔查询时,and 和or 操作都需要合并倒排表,这时就需要快速定位相同文档号,所以利用跳跃表来进行相同文档号查找
