HBASE的索引查询
一级索引
在逻辑上,HBase的表数据按RowKey进行字典排序, RowKey实际上是数据表的一级索引,由于HBase本身没有二级索引机制,基于索引检索数据只能单纯地依靠RowKey。
热点写
大部分场景下,我们的rowkey总是顺序增大的,存在比较明显的问题就是热点写,我们总是向最大的start key所在的region写数据,其次,由于热点,我们总是往最大的start key的region写记录,之前分裂出来的region不会被写数据,他们都处于半满状态,这样的分布也是不利的。如果在写比较频繁的场景下,数据增长太快,split的次数也会增多,由于split是比较耗费资源的。
热点写的解决思路
- 随机散列(hash):hash就是rowkey前面由一串随机字符串组成,随机字符串生成方式可以由SHA或者MD5方式生成,那么新增的rowkey就不再是按顺序增大的了,就可以解决写热点问题
- 分区式:这种方式类似于mysql中的分表,结合当前的region数目对id取模作为rowkey的前缀。但是一旦region自然分裂,分裂出来的分区号会是一样的,会有部分热点写问题出现,一般通过增多预分区或者加入多级分区来避免这个问题,通过合理设定预分区可解决热点写问题,同时减少split带来的性能消耗。
一级索引的局限
为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到RowKey中,这是HBase开发中极为常见的做法,但是无论怎样设计,单一RowKey固有的局限性决定了它不可能有效地支持多条件查询。通常来说,RowKey只能针对条件中含有其首字段的查询给予令人满意的性能支持,在查询其他字段时,表现就差强人意了,在极端情况下某些字段的查询性能可能会退化为全表扫描的水平,这是因为字段在RowKey中的地位是不等价的,它们在RowKey中的排位决定了它们被检索时的性能表现,排序越靠前的字段在查询中越具有优势(类似于mysql联合索引的最左原则),特别是首位字段具有特别的先发优势,如果查询中包含首位字段,检索时就可以通过首位字段的值确定RowKey的前缀部分,从而大幅度地收窄检索区间,如果不包含则只能在全体数据的RowKey上逐一查找,由此可以想见两者在性能上的差距.
二级索引的解决方案
原理:“二级多列索引”是针对目标记录的某个或某些列建立的“键-值”数据,以列的值为键,以记录的RowKey为值,当以这些列为条件进行查询时,引擎可以通过检索相应的“键-值”数据快速找到目标记录。由于HBase本身并没有索引机制,为了确保非侵入性,引擎将索引视为普通数据存放在数据表中,所以,如何解决索引与主数据的划分存储是引擎第一个需要处理的问题,为了能获得最佳的性能表现,我们并没有将主数据和索引分表储存,而是将它们存放在了同一张表里,通过给索引和主数据的RowKey添加特别设计的Hash前缀,实现了在Region切分时,索引能够跟随其主数据划归到同一Region上,即任意Region上的主数据其索引也必定驻留在同一Region上,这样我们就能把从索引抓取目标主数据的性能损失降低到最小。与此同时,特别设计的Hash前缀还在逻辑上把索引与主数据进行了自动的分离,当全体数据按RowKey排序时,排在前面的都是索引,我们称之为索引区,排在后面的均为主数据,我们称之为主数据区。最后,通过给索引和主数据分配不同的Column Family,又在物理存储上把它们隔离了起来。逻辑和物理上的双重隔离避免了将两类数据存放在同一张表里带来的副作用,防止了它们之间的相互干扰,降低了数据维护的复杂性,可以说这是在性能和可维护性上达到的最佳平衡。
方案:
- 将索引视为普通数据存放在数据表中(确保非侵入性)
- 将主数据和索引数据存放在同一张表里(为了能获得最佳的性能表现)
- 通过给索引和主数据的RowKey添加特别设计的Hash前缀,对Region完成预切分后(指定region数,禁止引擎自动切分),索引能够跟随其主数据划归到同一Region上。(从索引抓取目标主数据的性能损失降低到最小)
- 特别设计的Hash前缀还在逻辑上把索引与主数据进行了自动的分离,当全体数据按RowKey排序时,排在前面的都是索引,我们称之为索引区,排在后面的均为主数据,我们称之为主数据区
- 通过给索引和主数据分配不同的Column Family,又在物理存储上把它们隔离了起来
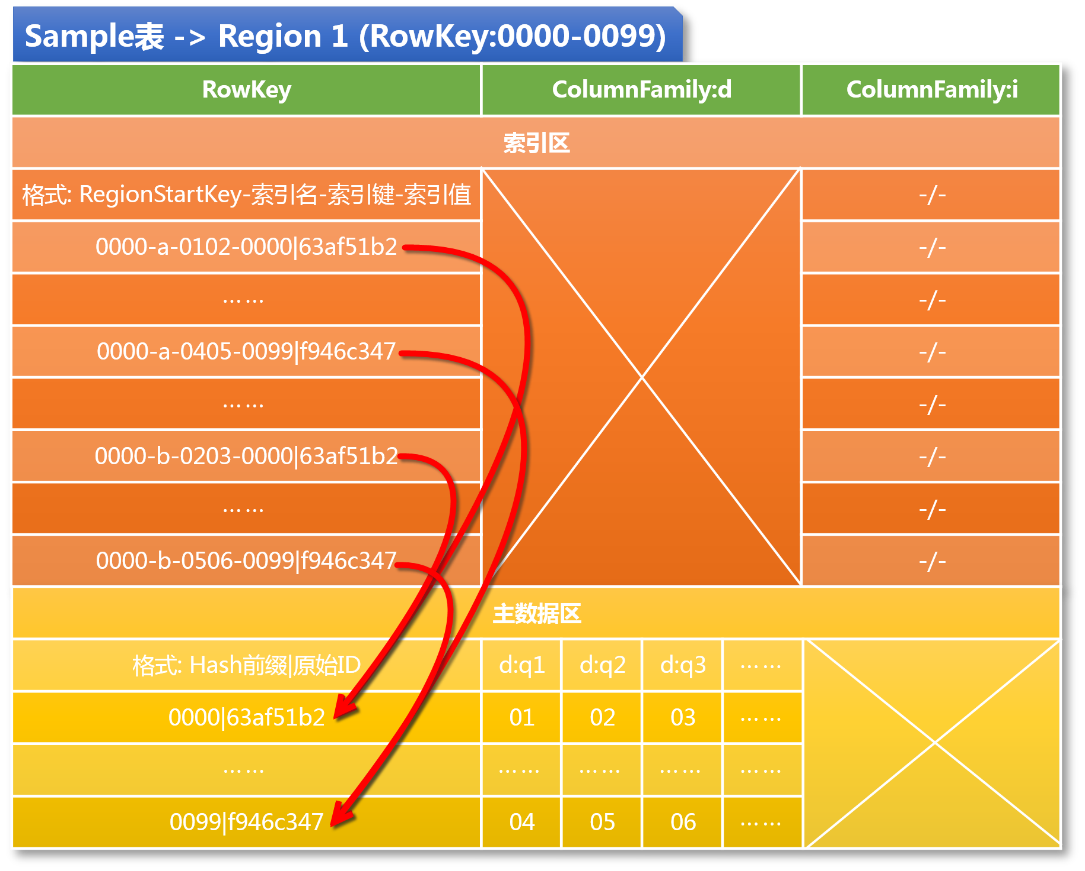
- 四位数字构成Hash前缀,范围从0000到9999,规划切分100个Region,则100个Region的RowKey区间分别为[0000,0099],[0100,0199],……,[9900,9999]
- 主数据的RowKey,它由四位Hash前缀和原始ID两部分组成,其中Hash前缀是由引擎分配的一个范围在0000到9999之间的随机值,通过这个随机的Hash前缀可以让主数据均匀地散列到所有的Region上
- 索引的RowKey,格式为:RegionStartKey-索引名-索引键-索引值
- 两种索引:a和b,索引a是为字段q1和q2设计的两列联合索引,索引b是为字段q2和q3设计的两列联合索引
- 假定需要查询满足条件q1=01 and q2=02的Sample记录,分析查询字段和索引匹配情况可知应使用索引a,也就是说我们首先确定了索引名,于是在Region 1上进行scan的区间将从主数据全集收窄至[0000-a, 0000-b),接着拼接查询字段的值,我们得到了索引键:0102,scan区间又进一步收窄为[0000-a-0102, 0000-a-0103),于是我们可以很快地找到0000-a-0102-0000|63af51b2这条索引,进而得到了索引值,也就是目标数据的RowKey:0000|63af51b2,通过在Region内执行Get操作,最终得到了目标数据